
Marlon Alagoda
Senior Developer (ehem.)
The current customer I’m working for gave us several requirements, including:
- Build a microservice platform on AWS
- Be able to move from AWS to Azure, bare metal or whatever within 30 days
The decision has been made and now we are developing and maintaining a k8s (short for Kubernetes) cluster on multiple AWS EC2 instances to deploy our services in. The hope is, that we can take the whole k8s cluster and move it to other servers, without spending (too much) time reconfiguring stuff, if Amazon suddenly gets a bad business partner, the law requires us to run services on self-hosted systems in future or for whatsoever reason. Is 30 days a viable period of time to move a production cluster with its services from one infrastructure provider to another?
Skip this if you know Kubernetes
Docker is king! Instead of having a complicated list of dependencies, like a specific Node.js version or a C lib your program needs, shipped with your application, you simply provide a Dockerfile. Docker isolates system resources and processes in so called containers, which behaves similar to (very) lightweight virtual machines. The following Dockerfile for a simple Node.js program creates a user app, copies the local files to the container, runs npm install to install the program’s dependencies, exposes the port 3000 and starts the application.
FROM node:8.4.0
RUN useradd -ms /bin/false app
ENV WORK=/home/app
COPY . $WORK
WORKDIR $WORK
RUN npm install && \
npm cache clean --force
EXPOSE 3000
USER app
CMD ["npm", "start"]
k8s is a container orchestration platform. You can run, upgrade, expose and manage your Docker (or rkt, but Docker is far more common) container with k8s. After you’ve installed k8s on one or multiple hosts you can deploy so called Pods in it. A Pod is an abstraction for Docker container. If the container above got deployed to the official Docker registry at docker.io/vuza/awesome-app the following k8s Pod description would be perfectly valid. Once applied, k8s would download the container and start it inside k8s.
apiVersion: v1
kind: Pod
metadata:
name: awesome-app
spec:
containers:
- name: awesome-app
image: docker.io/vuza/awesome-app
imagePullPolicy: Always
In addition to Pods, k8s provides other resource types like Deployments, Services, Ingress, … to up- and downscale service capacities, expose services, provide loadbalancing, security proxies, rolling updates, …
Our setup
We’re developing Node.js datapipes, moving data from Apache Kafka to multiple datasinks. At the very rough architecture overview below you can see that k8s is just another software artifact we have to take care of, but we still heavily rely on the underlaying resources.
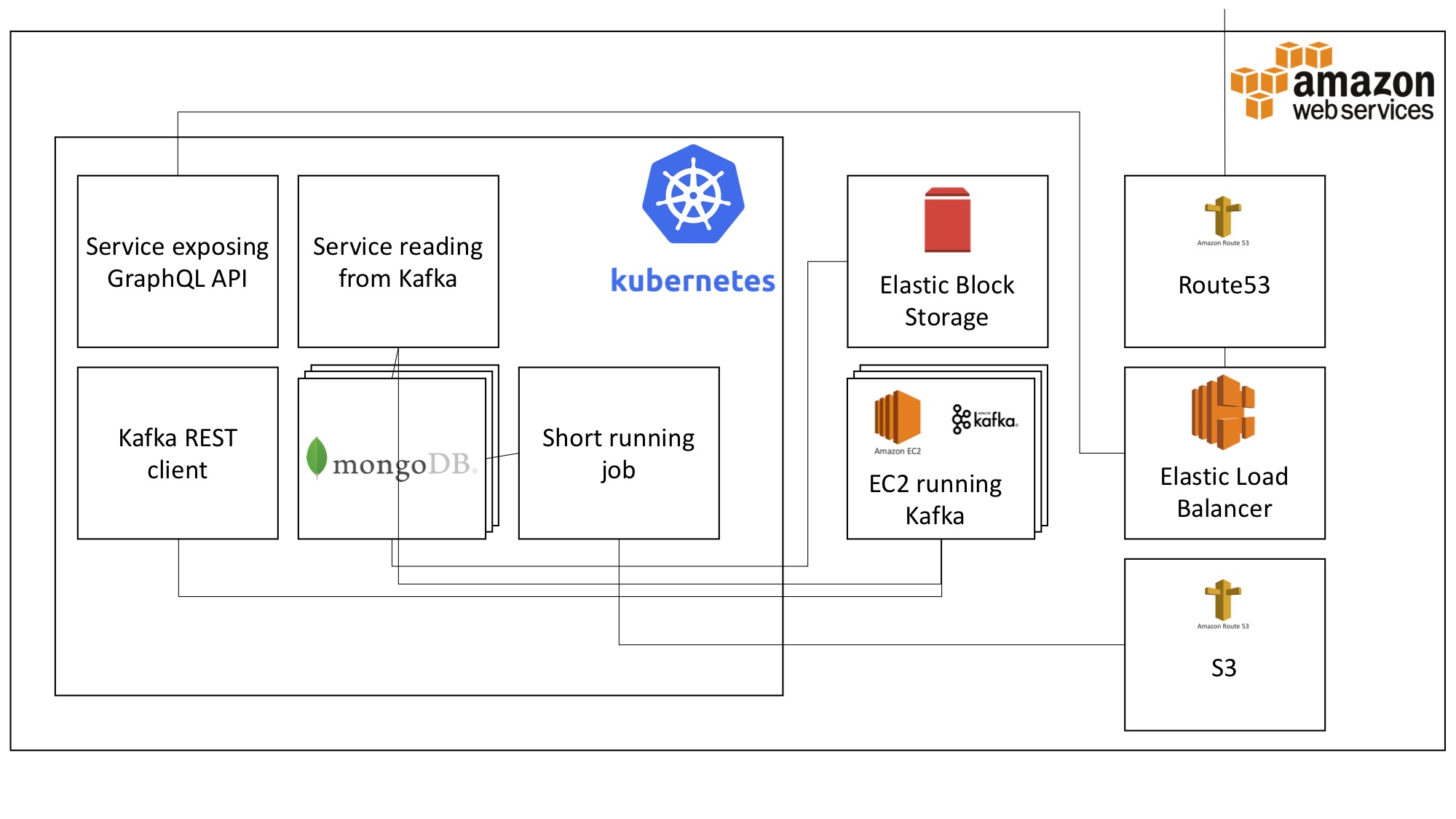
The AWS resources we rely on are part of the dependencies you cannot get rid of with k8s and which I’m going to explain in this post.
Dependencies towards our infrastructure provider
There are multiple configurations and dependencies which are specific to your infrastructure provider, even if you try to abstract your infrastructure provider with k8s! Since we use AWS, the following examples are very AWS specific, however the problems you need to solve and the concepts are the same for other providers.
1. DNS and load balancing
Exposed services need DNS and load balancer entries at AWS Route53 and ELB. We use external DNS to detect exposed services in our cluster and manage DNS and ELB entries at AWS. It reads annotations or specific k8s resources and wires up AWS components to make them available through the web. The following YAML file shows an Ingress definition. Ingress is a k8s resource which lets you configure URL path to service routing, SSL termination, basic auth, path rewriting and more HTTP proxy stuff.
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
annotations:
ingress.kubernetes.io/auth-secret: basic-auth
ingress.kubernetes.io/auth-type: basic
ingress.kubernetes.io/enable-cors: "true"
ingress.kubernetes.io/force-ssl-redirect: "true"
kubernetes.io/ingress.class: nginx
name: c***i
spec:
rules:
- host: c***n.a***4.c***t.***
http:
paths:
- backend:
serviceName: c***i
servicePort: 3000
path: /
The external DNS service detects this Ingress resource and automatically writes the matching entries at AWS‘ DNS.
The external DNS service can handle Google Cloud, AWS, Azure, CloudFlare, DigitalOcean, DNSimple and Infoblox. However you’ll have to make infrastructure provider specific configuration and authorization management.
2. Persistence
MongoDB needs a persistence layer, which of course is a resource of the underlying infrastructure provider, AWS in our case. There is a resource type called PersistentVolumeClaim in k8s. Depending on the underlaying infrastructure or desired storage provider it can claim volumes from there. Different storage providers are supported via plugins, including AWSElasticBlockStore, AzureFile, AzureDisk, CephFS, Cinder, GCEPersistentDisk, StorageOS, …
As long as you provide --cloud-proivder=aws as a startup parameter for your cluster and set the permissions inside your infrastructure provider accordingly everything works smoothly, as long as k8s natively supports your provider.
3. Filesystem encryption
You might want your data to be encrypted. That for file systems need to be en-/decrypted before k8s accesses it. AWS provides a very simple way to transparently en- and decrypt your data after and before your application accesses it. Since this has nothing to do with k8s, you need to make those settings at your infrastructure provider.
4. Authorization to low(er) level components
AWS provides an authorization concept called IAM (Identity and Acccess Management). Our jobs need to be authorized to access the given AWS S3 bucket, our k8s cluster needs to be authorized to write Route53 entries and our Grafana needs the authorization to read performance metrics from our infrastructure. This concept is very AWS specific. We wrote our authorization concept down in Ansible, which we not only use as configuration management, but partly as a living documentation as well. We would have to make conceptional changes if we move away from AWS. Currently we use the following Ansible role to deploy a specific IAM policy, which requires another AWS specific Ansible role, requesting different keys and a session token, which means there are many infrastructure provider specific dependencies.
- name: Apply S3 bucket policy to Kubernetes cluster node role
block:
- iam_policy:
iam_type: role
iam_name: nodes.{{ cluster_name }}
policy_name: import.initialload.{{ cluster_name }}
state: present
policy_document: "{{ role_path }}/files/initialload-s3-policy.json"
aws_access_key: "{{ assumed_role.sts_creds.access_key }}"
aws_secret_key: "{{ assumed_role.sts_creds.secret_key }}"
security_token: "{{ assumed_role.sts_creds.session_token }}"
5. You need etcd to run k8s
„etcd is used as Kubernetes’ backing store„. That for etcd obviously needs to be installed outside of k8s. That means you cannot abstract it with k8s and an infrastructure provider change would lead to re-installing etcd, including fail-safe clustering and backups, since it’s a critical system component. Of course etcd not only needs to be as fail-safe as possible, it also requires a persistence layer with encryption, backups and restoring concepts, which all is very infrastructure specific.
6. Network Connectivity
When installing k8s on a couple of EC2 instances, it has to be made sure your container, pods and services, spread all over the cluster, can communicate. To archive this a very common solution is flannel.
Flannel runs a small, single binary agent called flanneld on each host, and is responsible for allocating a subnet lease to each host out of a larger, preconfigured address space
Since flannel runs outside of k8s, on whatever hosts you choose, networking is a further dependency torwards your infrastructure provider you cannot get rid of.
Then why use Kubernetes at all?
When reading this article you could get the idea that using k8s is a bad idea at all, which it isn’t! I’ve listed a couple of dependencies towards your infrastructure, which you don’t loose when you use k8s. Of course there are many dependencies which you can get rid of. As an example a colleague pointed out to me, that your devops people don’t have to re-learn how to deploy, update, debug and scale services, every time you change your infrastructure provider but can rely on their k8s knowledge, which is a huge argument. However since the decoupling elements of k8s are way more obvious I wanted to make sure nobody expects miracles, when it comes to changing the underlaying infrastructure.
Bottom line ____________
Bottom line I’d argue using k8s might be a great idea, because it’s great at orchestrating containers. However you will spend a lot of time configuring and operating it! If you want to change your infrastructure provider, you need to rebuild your k8s cluster on another infrastructure provider, which is, due to the above listed dependencies, very expensive as well. Deploying your services on AWS first and then move them to Azure, Docker Swarm or k8s itself will be cheaper, since you don’t have to run your container orchestration tool by your self. Make sure to embrace the tools you use. If you use k8s, make sure you use all advantages and not only use it for the sake of infrastructure abstraction, which wouldn’t justify its use.
Also keep in mind that using k8s is a vendor-lock as well. Even if k8s is open source, Google is the biggest contributer. If Google wants to remove functionality you rely on, you’ll end up in the same troubles you have with other vender-locks.
You might want to have a look at Kubernetes as a Service from Google, AWS or Platform9 which has the potential to make this whole discussion obsolete.
Not enough?
If you are interested in container orchestration, k8s, cloud, infrastructure, … in more detail, have a look at the following links.