
Felix Zolitschka
Managing Consultant und Experte für Big Data and ML
Der zunehmende Einsatz von Machine Learning (ML) in der Praxis erfordert bei Unternehmen tiefes Expertenwissen in ML und Data Science und ist oft mit hohen budgetären sowie zeitlichen Aufwänden verbunden. Als Mitigation verspricht Automated Machine Learning (AutoML) den ML-Prozess zu automatisieren und somit deren Anwendung zu vereinfachen. Doch welches Potenzial steckt tatsächlich hinter AutoML-Lösungen? Im Rahmen eines Innovation Labs [1] hat Senacor das Leistungsversprechen von AutoML-Frameworks analysiert und mit dessen Einsatz eine Top 5-Platzierung bei mehr als 10.000 Teilnehmern in einer bekannten ML-Challenge erreicht.
Machine Learning ist in der Praxis wesentlich von ML-Experten abhängig
Heute wird in nahezu allen Branchen künstliche Intelligenz in Form von maschinellem Lernen eingesetzt. Durch die großen Forschungsfortschritte in den vergangenen Jahren hinsichtlich der Vielfalt und Leistungsfähigkeit (Effektivität und Effizienz) von ML-Algorithmen sind diese mittlerweile Kernbestandteil vieler digitaler Services geworden.
Der ML-Prozess (siehe Abbildung 1) lässt sich im Kern als ein iterativer und explorativer Prozess beschreiben, bei dem in den meisten Schritten eine große Menge an Stellschrauben anwendungsspezifisch zu konfigurieren sind. Oftmals führt nur Intuition, Domänen- und ML-Erfahrung, gezieltes Experimentieren und iterative Optimierung vieler einzelner Stellschrauben zu guten Ergebnissen. Hieraus resultiert, dass der Erfolg einer ML-Anwendung zum einen wesentlich von menschlichen Experten (Data Scientists und Data Engineers) abhängt und zum anderen einen hohen Aufwand mit sich bringt. Dadurch stehen Unternehmen sowohl vor einer hohen Einstiegshürde als auch vor erhöhtem Bedarf an Expertenwissen für die flächendeckende und produktive Implementierung.
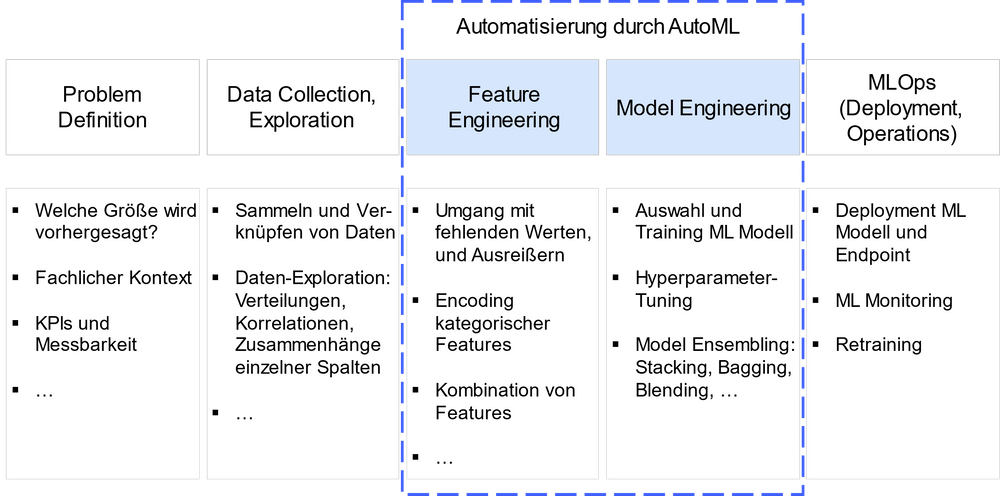
Abbildung 1: ML-Prozess und Leistungsversprechen von AutoML
Reduktion der Komplexität und des Aufwands im ML-Prozess durch AutoML
Die hohe Komplexität der ML-Aufgaben hat somit substanziell zur Nachfrage nach standardisierten Methoden und einer Automatisierung des maschinellen Lernens beigetragen. Das Ziel hierbei ist, die einfache Anwendung und Optimierung diverser ML-Algorithmen ohne tiefgreifendes Expertenwissen zu ermöglichen.
Der hieraus resultierende Forschungsbereich, der auf die fortschreitende Automatisierung des maschinellen Lernens abzielt, wird Automated Machine Learning genannt. Die Größe des AutoML-Marktes wächst aktuell rasant, da die Technologie immer beliebter wird. Ein Bericht von Research and Markets aus dem Jahr 2020 besagt, dass der Markt im Jahr 2019 einen Umsatz von 0,3 Milliarden US-Dollar generiert hat und dieser bis 2030 voraussichtlich auf 14,5 Milliarden US-Dollar ansteigen wird.
Die Anwendung von AutoML verspricht hierbei, im Vergleich zum klassischem ML, die nachfolgenden Punkte zu gewährleisten:
- Reduzierung der Einstiegshürde für ML: Durch eine Integration diverser ML-Algorithmen und der automatisierten Konfiguration und Optimierung der verfügbaren Stellschrauben ist kein tiefes Expertenwissen notwendig.
- Erhöhung der Liefergeschwindigkeit: Die Dauer bis zur Erreichung guter Ergebnisse, z.B. beim Prototyping oder bei Ad hoc-Predictions, kann reduziert werden.
- Erzielung von besseren Ergebnissen (höhere Effektivität): Durch algorithmische Optimierung einzelner Schritte im ML-Prozess, können potenziell bessere Ergebnisse erzielt werden.
- Optimierter Einsatz von Ressourcen (höhere Effizienz): Auf Basis der Automatisierung des ML-Prozesses wird manueller Aufwand reduziert und Key Know-How-Träger entlastet.
Mit Hilfe einer Klassifikation von Brunnen in Afrika zu einer Bewertung von AutoML-Frameworks
Zur Analyse des Potenzials von AutoML haben wir in unserem Innovation Lab aus den 16 bekanntesten AutoML-Lösungen am Markt sechs AutoML-Frameworks (siehe Abbildung 2) sowie die klassische Lösung auf Basis von ML-Experten zur Evaluierung ausgewählt. Um die Leistungsfähigkeit dieser AutoML-Frameworks auf die Probe zu stellen, ist eine (auch für ML-Experten) herausfordernde Problemstellung erforderlich. Wir haben uns für ML-Challenge „Pump it Up: Data Mining the Water Table“ von Driven Data entschieden. Das Ziel der Challenge ist es, den Zustand eines Wasserbrunnens in Tansania anhand von diversen, tabellarischen Informationen zu ermitteln (u.a. den Eigenschaften des Brunnens, den geographischen Begebenheiten, der Demographie und der politischen Region). Besonders herausfordernd war daran für uns, dass der zugrundeliegende Datensatz dieser Challenge sowohl numerische als auch kategorische Werte, diverse Ausreißer und fehlende Werte enthält. Somit erfordert die Verarbeitung dieses Datensatzes beispielsweise ein umfangreiches Preprocessing vor der Anwendung des Modelltrainings und stellt auch ML-Experten bereits vor Herausforderungen.
Durch die praktische Anwendung der ausgewählten Frameworks zeigte sich, dass durchgängig alle Frameworks bereits mit den Standardeinstellungen und auf Rohdaten eine gute Performance aufweisen. Der Funktionsumfang, die Konfigurationstiefe sowie die Güte der Dokumentation unterscheiden sich hierbei jedoch stark voneinander. Dies ist unter anderem darin begründet, dass die Frameworks teilweise unterschiedliche Zielgruppen (ML-Einsteiger oder ML-Experten) und ML-Bedürfnisse (Preprocessing, Model Engineering, Betrieb (MLOps)) adressieren (Ergebnisse siehe Abbildung 2).

Abbildung 2: Ergebnisse und Bewertung ausgewählter AutoML-Lösungen
AutoML-Frameworks als sinnvolle Ergänzung jeder Analytics Toolbox
Am praktischen Anwendungsbeispiel der AutoML-Frameworks durch die ML-Challenge wurden – insbesondere im Vergleich zu den zeitgleich verprobten klassischen Lösungen unserer ML-Experten – bessere Ergebnisse mit einem deutlich geringeren Einsatz an Zeit und Expertenwissen erzielt. Auch im Vergleich zu den restlichen 10.531 Teilnehmern der Challenge belegt unsere Platzierung unter den Top 5 aller Teilnehmer die hohe Effektivität von AutoML-Frameworks (siehe Abbildung 3).
Insgesamt haben alle AutoML-Frameworks die oben genannten Lieferversprechen erfüllt und stellen aus unserer Sicht eine sinnvolle Ergänzung der Analytics Toolbox eines Unternehmens
dar! Die Auswahl eines geeigneten AutoML-Framework ist hierbei allerdings immer abhängig von der Zielsetzung, der benötigten Automatisierung im ML-Prozess sowie den Rahmenbedingungen, wie beispielsweise der Verfügbarkeit von ML-Experten. Auf dem Markt existiert eine Vielzahl an AutoML-Lösungen, die je nach Ausgestaltung einen mehr oder weniger großen Anteil des ML-Prozesses abdecken. Hierdurch werden ML-Experten in Unternehmen entlastet sowie eine schnelle und einfache Erstellung guter ML-Lösungen ermöglicht.
Grundsätzlich ist allerdings bei einer Einführung von AutoML immer auf einen erhöhten Hardwarebedarf zu achten. Werden AutoML-Lösungen punktuell durch ML-Experten ergänzt und somit weiteres Domänenwissen und Erfahrung integriert, kann der Hardwarebedarf jedoch teilweise reduziert und die AutoML-Lösung noch effektiver gestaltet werden.
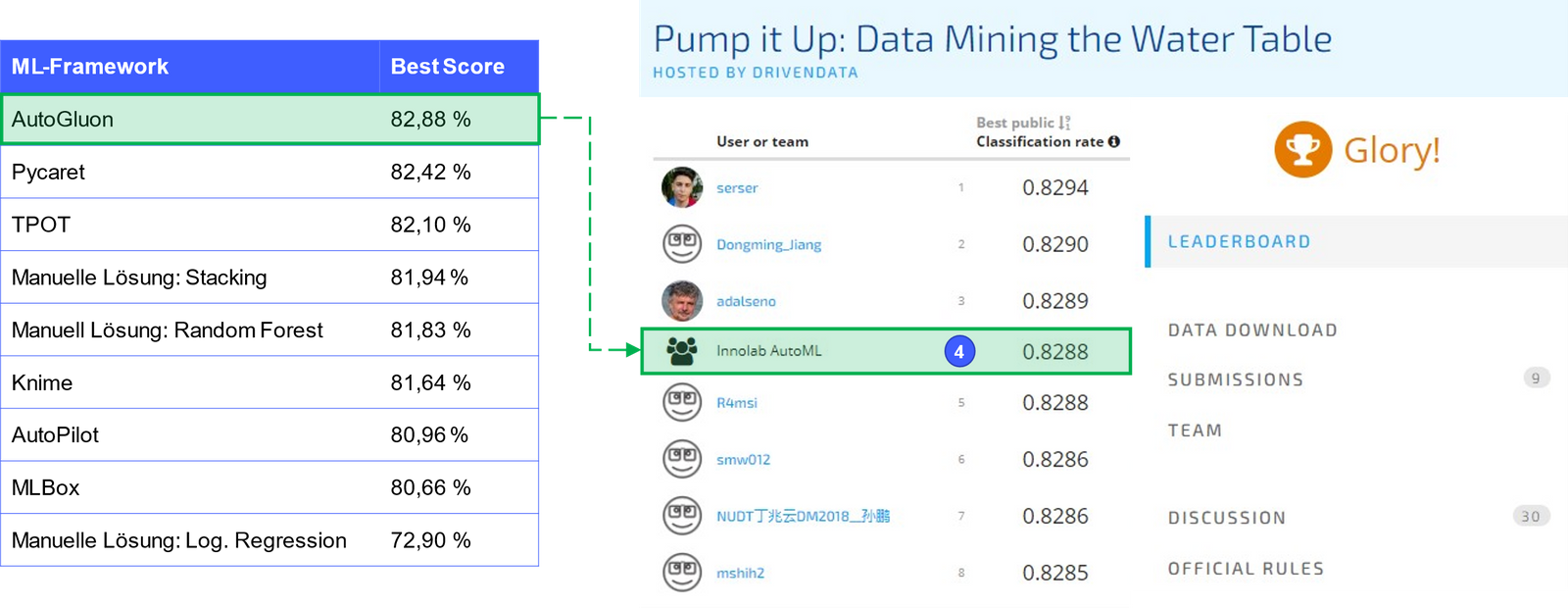
Abbildung 3: Ergebnisse und Platzierung bei der ML-Challenge
Senacor hat im Laufe der Jahre umfassende Erfahrung sowohl mit Advanced Analytics-Use Cases als auch mit dem Aufbau von Big Data-Plattformen gesammelt, die passgenau das individuelle Geschäftsmodell unserer Kunden unterstützen.
Für einen Austausch zu Advanced Analytics oder Beratung zu AutoML stehen unsere Experten gern zur Verfügung: Dr. Werner Steck, Leiter Expertenkreis Big Data & Advanced Analytics; Felix Zolitschka, Experte Machine Learning und Künstliche Intelligenz oder https://senacor.com/retail-finance/retail-finance-leistungen-technologie/
[1] Das Innovation Lab bei Senacor ist ein Forschungsformat, für das jeweils mehrere Senacor-Mitarbeiter aus ihrem Projekt herausgehen und sich in der Regel 2-4 Wochen mit einem Thema intensiv auseinandersetzen und forschen. Die Ergebnisse werden den Kollegen in der Form von z.B. Knowledge Talks sowie der Öffentlichkeit in Form von z.B. Blogbeiträgen oder Vorträgen bei Konferenzen zur Verfügung gestellt.