
Michael Menzel
Partner Principal Architect
Dies ist Teil 1 einer Blog-Serie über reaktive Architekturen mit RxJava. Einführung und Übersicht finden sich hier.
Reaktive Konzepte und Frameworks erfreuen sich immer größerer Beliebtheit, nicht zuletzt durch steigende Anforderungen an die Performance und Verfügbarkeit von Web-Anwendungen. In Zeiten der Digitalisierung ändert sich die Kundenerwartung deutlich – eine permanente Verfügbarkeit von Applikationen ohne Ausfälle und Wartungsintervallen, schnelle Innovationszyklen und eine exzellente Nutzererfahrung durch eine hohe Reaktionsfähigkeit der Applikationen sind ein Muss. Damit ist eine zeitgemäße Anwendung hoch interaktiv: Auf Nutzeraktionen muss in kurzer Zeit ohne Ausfälle reagiert werden. Zeitgleich müssen die Anwendungen aber auch mit einem steigenden Daten- und Nutzerwachstum skalieren können.
Reaktive Systeme nach dem reaktiven Manifest
Reaktive Architekturen liefern eine Antwort auf die zentrale Frage, wie hoch interaktive Systeme gebaut werden können, die unter hoher Last und mit hohem Datenvolumen performant operieren.
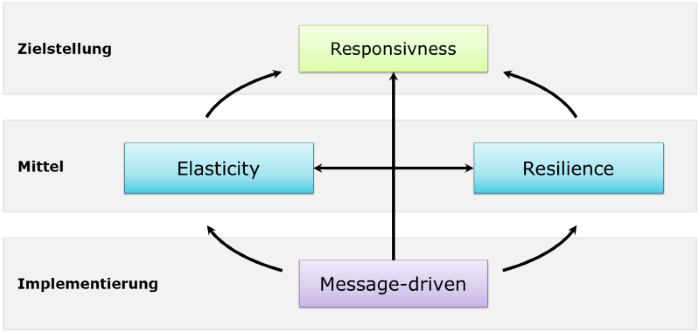
Abbildung 1: Reaktive Systeme nach dem reaktiven Manifest
Das Grundlegende Konzept wird durch das reaktive Manifest (http://www.reactivemanifesto.org/) beschrieben. Wie in Abbildung 1 dargestellt, basiert eine hohe Interaktivität (Responsivness) auf den Prinzipien Elastizität, Fehlertoleranz und eine Nachrichten-getriebene Kommunikation:
1. Responsivness
Die Zielstellung reaktiver Systeme ist eine hohe Interaktivität von Anwendungen: Auf Nutzeraktionen muss in kurzer Zeit geantwortet werden. Diese Eigenschaft darf das System auch unter steigender Last und unter hohem Datenvolumen nicht verlieren.
2. Elasticity
Elastizität fordert die dynamische und bedarfsgesteuerte Bereitstellung von Ressourcen. Schließlich soll die Anwendung auch an Lastspitzen – bspw. vor Weihnachten – performant und verfügbar bleiben.
Dabei geht die Elastizität über einen klassischen Scale-Up-Ansatz hinaus, bei der die Ressourcennutzung eines einzelnen Servers maximiert wird. Erforderlich ist ein Scale-out-Ansatz mittels verteilter Services, die redundant Funktionalität bereitstellen und unabhängig skaliert werden können.
3. Resilience
Fehlertoleranz setzt zur Ausfallsicherheit auf Replikation von Ressourcen und geht daher mit der Elastizität einher. Überdies müssen Fehlersituationen – wie Timeouts – schnell erkannt werden (Fail Fast) und nach Möglichkeit durch Fallback-Mechanismen kompensiert werden. In jedem Fall müssen Fehler isoliert behandelt werden und dürfen sich nicht mit Seiteneffekten durch das System ziehen. Beispielsweise sollte eine Finanzübersicht auch dann noch funktionieren, wenn Services für einzelne Produkte nicht verfügbar sind.
4. Message-driven
Ein asynchroner Nachrichtenaustausch ist die Grundvoraussetzung von entkoppelten und skalierbaren Komponenten. Blockierende und zustandsbehaftete Aufrufe über Systemgrenzen hinweg haben einen äußerst negativen Einfluss auf die Stabilität des Gesamtsystems. Somit ist ein nachrichtenbasierter Ansatz die Basis für die Gewährleistung von Elastizität und Fehlertoleranz. Überdies ermöglicht ein solcher Ansatz auch einen push-basierten Datenaustausch und stellt damit die Grundlage einer reaktiven Architektur dar. Teildaten können zur Weiterverarbeitung an andere Komponenten oder das Frontend gestreamt werden. Wenn beispielsweise für eine Nutzersuche Informationen aus verschiedenen Systemen aggregiert werden müssen, dann können durch einen nachrichtenbasierten Ansatz bereits verarbeitete Nutzer an den Client übermittelt werden. Dadurch werden dem Nutzer auch bei sehr großen Trefferlisten schnell Ergebnisse angezeigt und die gefühlte Geschwindigkeit der Anwendung steigt signifikant.
Eine asynchrone Verarbeitung macht den Unterschied
Reaktive Architekturen sind hochverteilte Systeme, die mit thread-basierten Frameworks und Programmiermodellen nur schwer umzusetzen sind. Klassische Applikationserver basieren auf synchroner Programmierung mit geteiltem Zustand (shared mutable state), Threads, blockierender Synchronisierung (Locks) und blockierenden Aufrufen.
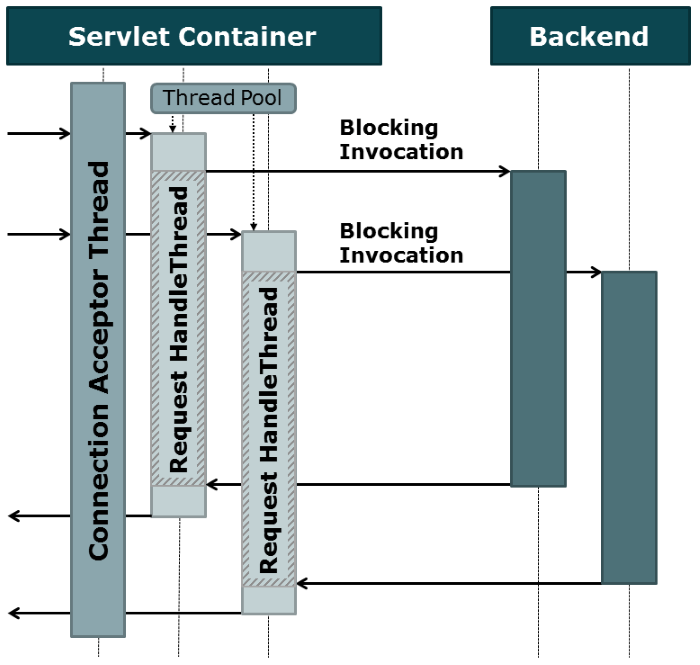
Abbildung 2: Thread-basierte Request-Behandlung im Servlet-Container
Abbildung 2 zeigt eine thread-basierte Request-Behandlung am Beispiel eines Servlet-Containers. Für jeden neuen HTTP-Request wird ein neuer Thread erzeugt, auf dem die Service-Logik ausgeführt und die Anfrage bearbeitet wird. Die Logik kann dann synchron programmiert sein, wobei Backend-Systeme blockierend abgefragt werden. Diese blockierenden Aufrufe können dann auch wieder auf eigenen Threads ausgeführt werden (bspw. mit Hystrix), um dem Aufruf zu isolieren und explizit Timeout setzen zu können.
Allerdings geht dieses Modell geht mit einem Overhead zur Erzeugung und Verwaltung der zusätzlichen Threads einher. Die Kosten der Thread-Erzeugung (Speicherallokation, Systemaufrufe, etc.) können zwar über Thread-Pools abgefangen werden, dennoch geht die Nutzung von Threads mit zusätzlichem Speicherbedarf sowie eines Performanceverlustes durch Kontextwechsel einher. Zudem will die Größe der Thread-Pools in Hinblick auf das Gesamtsystem ausgewogen gewählt sein. Thread-Pools können bei zu kleiner Dimensionierung schnell der Grund für Performance-Probleme sein und sind somit keine gute Voraussetzung für eine reaktive Architektur, die automatisch skalieren soll.
Soll ein Volumen von 10 000 Nachrichten gleichzeitig bearbeitet werden können, ist ein zustandsloser, asynchroner Ansatz notwendig. Aufgerufene Komponenten informieren, wenn Daten zur Verarbeitung bereit stehen und schieben diese Daten dann zur weiteren Verarbeitung an eine Event Loop.
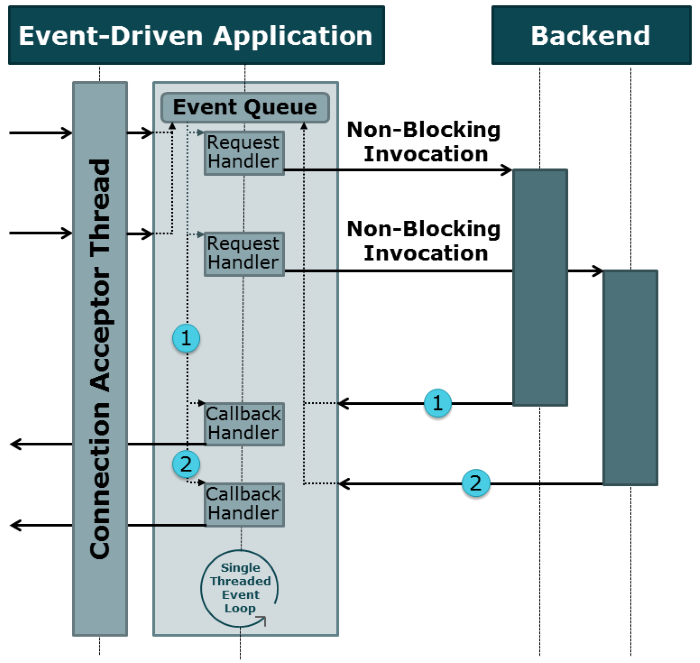
Abbildung 3: Event-Loop-basierte Request-Behandlung
Abbildung 3 illustriert die alternative Verarbeitung von Requests auf Basis einer Event-Loop. Anfragen werden als Events in eine Queue eingereiht und durch die Event-Loop nacheinander verarbeitet. Nicht-blockierende Backendaufrufe registrieren Callbacks als Event-Handler, die bei Bereitstellung der Daten durch die Backend-Systeme aufgerufen werden. Ein großer Vorteil dieses Modells ist, dass eine Event-Loop auf einem Thread ausgeführt werden kann. Ein Datenzugriff kann immer ohne die Notwendigkeit zur blockierenden Synchronisierung und ohne die Gefahr einer schwer zu identifizierenden Race-Condition erfolgen, die nebenläufige Programmierung so kompliziert und fehleranfällig macht.
Nachrichten- vs. Eventverarbeitung
Reaktive Programmierung ist event-getrieben, um Daten asynchron in die weitere Verarbeitung schieben zu können, und basiert auf der Verwendung von kurzlebigen Funktionsketten. Hingegen sind reaktive Systeme nachrichtengetrieben mit dem Fokus auf Fehlertoleranz und Elastizität durch eine entkoppelte Kommunikation.
Der Hauptunterschied zwischen einem nachrichtengetriebenen System und einem event-getriebenen, datenflussgesteuerten Modells liegt in der Art der Informationsverteilung. Nachrichten sind gerichtete Informationen mit einem klaren Empfänger, während Events Fakten darstellen, die Konsumenten verfolgen können. Bei einer nachrichtengestützten Kommunikation können unterschiedliche Kommunikationspattern (Send/Reply, Publish/Subscribe) genutzt und explizit Timeouts gesetzt werden. Bei Events gibt es keine expliziten Empfänger – beispielsweise bei Tastatureingaben im Browser. Events können über einen Event-Handler abgefangen und als Nachrichten gekapselt an ein anderes System gesendet werden, um dort als Events weiterverarbeitet zu werden.
Die in Abbildung 3 gezeigte event-Loop-basierte Verarbeitung kommuniziert nachrichtenbasiert mit den Backendsystemen, aber verarbeitet die Aufrufergebnisse dann event-basiert.
Eine Frage des Programmiermodells
Somit stellt die eine asynchrone Verarbeitung von Eventfolgen die Grundlage von reaktiven Systemen. Programmiermodelle zur asynchronen Datenverarbeitung werden im zweiten Teil dieser Blog-Serie behandelt: