
Sebastian Neb
Lead Developer

Max Rigling
Managing Consultant
Das Thema Cloud ist mittlerweile allgegenwärtig. Fast jeder Besitzer eines Smartphones oder eines Computers hatte bereits direkt oder indirekt Kontakt mit Cloud Technologien – allein jeder Google- oder Apple-Account besitzt einen kostenlosen Cloud Speicher. Start-Ups setzen schon länger für ihr (Service-) Infrastruktur auf die Cloud, aber mittlerweile folgen auch mehr und mehr Banken und Versicherungen.
Laut einer aktuellen Gartner-Studie wird der Cloud-Markt in diesem Jahr erstmals ein Volumen von mehr als 300 Mrd. US-Dollar erreichen. Bereits 2020 haben die Ausgaben für Cloud-Infrastrukturen zum ersten Mal diejenigen für klassische Data Center übertroffen. Dazu tragen auch die deutschen Finanzinstitute einiges bei: 72 Prozent, das zeigt eine aktuelle Lünendonk-Studie, sind bereits in der Cloud oder auf dem Weg.
Migration in die Cloud – einfach so?
Für die Unternehmen spielen bei der Migration in die Cloud verschiedene Überlegungen eine Rolle. Im Bankenumfeld ist der Hauptfokus, nach unseren Beobachtungen aktuell, die operativen Kosten (RTB) zu senken sowie schneller und einfacher neue Produkte zu entwickeln und zu ihren Kunden zu bringen. Genau hier platzieren sich die oben genannten Anbieter mit dem Versprechen simpler, skalierbarer Infrastrukturlösungen als willkommene Alternative für die Banken-IT, welche mit komplexen Legacy-IT Systemen in eigenen Datacenter zu kämpfen haben.
Blickt man allerdings einmal etwas genauer hin, zeigen sich zwei konkrete Probleme: Die Angebote der Cloud-Anbieter werden von Jahr zu Jahr größer und komplexer und bieten mehr und mehr Services, die zumeist Anwendungsfälle lösen, welche die wenigstens Banken haben. Zudem gelten für Finanzinstitute insbesondere in Deutschland hohe Anforderungen und strenge Regularien, welche die Nutzung der Cloud zwar nicht verhindern, aber gewisse Mehraufwände bedeuten.
Beide Probleme führen in ihrer Konsequenz zu einem erhöhten Bedarf an einem breiteren und zumeist auch tieferen Wissen in der Entwicklung und Betrieb. Es reicht nicht mehr „einfach einen Java Service zu entwickeln“. Man muss bedenken, dass dieser Service auf einer potentiell hoch skalierbaren Infrastruktur läuft und auf Containern basiert. Gekoppelt mit der immer stärkeren Auflösung der innerbetrieblichen Grenzen bis zu einem DevOps-Modell ergeben sich für die Entwickler:innen (im umfassenden Sinne für alle Kolleg:innen im Bereich Dev&Ops) dementsprechend nicht nur die fachlichen und technischen Anforderungen an die Anwendungsentwicklung sondern insbesondere auch an die Bereitstellung von hochverfügbaren Infrastrukturkomponenten. Diese müssen den hohen Sicherheitsanforderungen gerecht werden und bestenfalls auf Knopfdruck verfügbar sein, flankiert von automatischen Test- und Freigabeprozessen.
Die reine Verortung innerhalb der IT eines Unternehmens oder sogar nur in der Anwendungsentwicklung wird dementsprechend kaum Erfolg bringen, bezieht sie doch die wichtigen Supportfunktionen wie Compliance, Security oder Legal nicht ein. Im schlimmsten Fall führt so ein Vorgehen zur Verlangsamung der gesamten Transformation.
Eine Cloud-Transformation bedeutet die Umstellung der gesamten Organisation. Hier erfordert es ein Umdenken in allen Bereichen des Unternehmens mit der ausschließlichen Orientierung am zu schaffenden Kundenmehrwert. Kunden interessieren sich selten dafür, ob die genutzte Anwendung auf selbst gewarteter Infrastruktur des Unternehmens betrieben wird oder moderne Ansätze wie Infrastructure as a Service (IaaS) oder sogar Platform as a Service (PaaS) bzw. Software as as Service (SaaS) genutzt werden. Die Vielzahl der Begriffe lässt es bereits erahnen, dass es mit einem reinen “Lift & Shift” der Anwendungslandschaft nicht getan ist und die reine Anzahl an migrierten Anwendungen eine hinreichend schlechte Kennzahl ist.
Beispiel einer Großbank – Herausforderungen und Lösungen
Aktuell begleiten wir als Senacor die Cloud-Migration einer der führenden deutschen Großbanken und möchten hier Einblicke in unsere gewählte Teamstrategie gewähren und auf Probleme und Lösungen hinweisen, welche uns dort erwartet haben. Insbesondere möchten wir dabei auf die Bereitstellung der Cloud-Infrastruktur eingehen und unseren Lösungsweg für die zuvor beschriebene Problemstellung skizzieren.
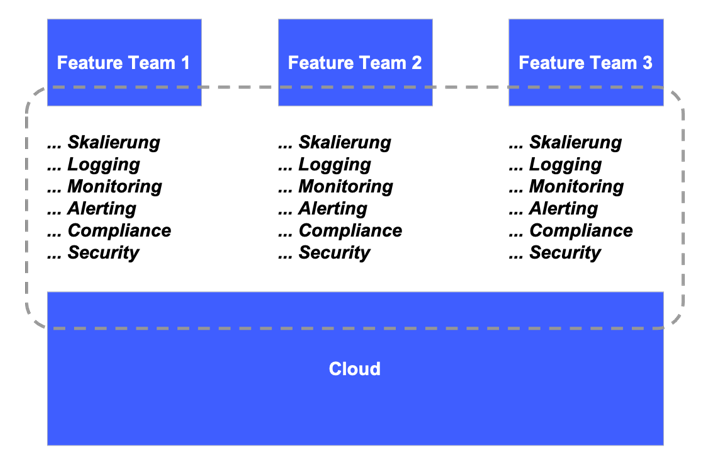
Projektstruktur mit cross-funktionalen, domänenorientierten Featureteams
Die gewählte Vorgehensweise im Projekt orientiert sich an skalierten, agilen Methoden und nutzt zumeist das SAFe-Framework mit mehreren cross-funktionalen Featureteams, welche in ihrer jeweiligen fachlichen Domäne fachliche Funktionalitäten entwickeln.
Bezüglich der Infrastrukturbereitstellung ergeben sich in diesem Setup nun mehrere Problemstellung:
Eines der ersten Probleme ist die Priorisierung von Infrastrukturthemen in Featureteams. Jedes Featureteam hat ein Set von ähnlichen Anforderungen welche die zu Grunde liegende Infrastruktur (bspw. ein Kubernetes Cluster) erfüllen muss. Dazu gehören zum Beispiel Scalability, Logging, Monitoring, Alerting sowie Compliance und Security Anforderungen. Muss jedes Team diese Anforderungen nun eigenständig erfüllen, bedarf es einem hohen sowie breiten Skillset bei den Entwickler:innen und führt unweigerlich zu einem hohen Bedarf an teamübergreifenden Absprachen, sodass Aufgaben nicht doppelt geplant und erledigt werden.
Zusätzlich benötigt der jeweilige Product Owner zu seinem fachlichen Wissen ein hohes technisches Verständnis. Zum einen um zu verstehen, ob technische Aufgaben notwendig sind und zum anderen, um bewerten zu können, wie wichtig diese für seine Aufgabenpriorisierung sind. Unsere Projekterfahrung hat uns gezeigt, dass bei einem solchen Setup sehr häufig technische Aufgaben schlicht nicht priorisiert werden. Spätestens wenn Deadlines erfüllt werden müssen, führt dies immer zu einem zentralen Team, welches kurzfristig etwas entwickeln oder absichern muss. Dies genügt meist nicht den Anforderungen der Featureteams und erfüllt die zentralen Policies meist nur mit manuellen Workarounds.
Eine weitere Herausforderung sind die im Regelfall bereits vorhandenen, zentralen Teams in großen Banken und Versicherungen. Es gibt meist ein dediziertes Team, welches sich um das Netzwerk kümmert, ein weiteres Team kümmert sich zentral um Developer Tooling wie Source Code Repositories und Build Tools. Weitere Teams sind verantwortlich für bspw. das grundlegende Aufsetzen der Cloud für das gesamte Unternehmen (User Accounts, Cloud Projekte, zentrale Ressourcen wie ein Artifact-Store). Es bedarf also als einfaches Vorhaben einer zusätzlichen großen übergreifenden Absprache mit diesen zentralen Teams. Wenn jedes Feature-Team dies separat erledigen muss, entsteht zusätzliche Mehrarbeit und ein sehr hohes Potential für Fehlkommunikation.
Unsere Lösung? Eine als Produkt gedachte, zentrale Infrastrukturplattform
Um diese genannten Probleme von Tag 1 an zu verhindern, haben wir uns bereits frühzeitig für ein Platform Team (wir haben es „Cloud Readiness“ genannt) entschieden. Dieses kapselt die zentralen Abhängigkeiten und stellt den Featureteams eine als Produkt gedachte Plattform bereit, auf der diese ihre Workloads und Services betreiben können. Da dieses zentrale Team ausschließlich für die Bereitstellung einer Plattform mit den benötigten Capabilities zuständig ist, fallen hier auch keine Features aufgrund von fehlender Priorisierung herunter.
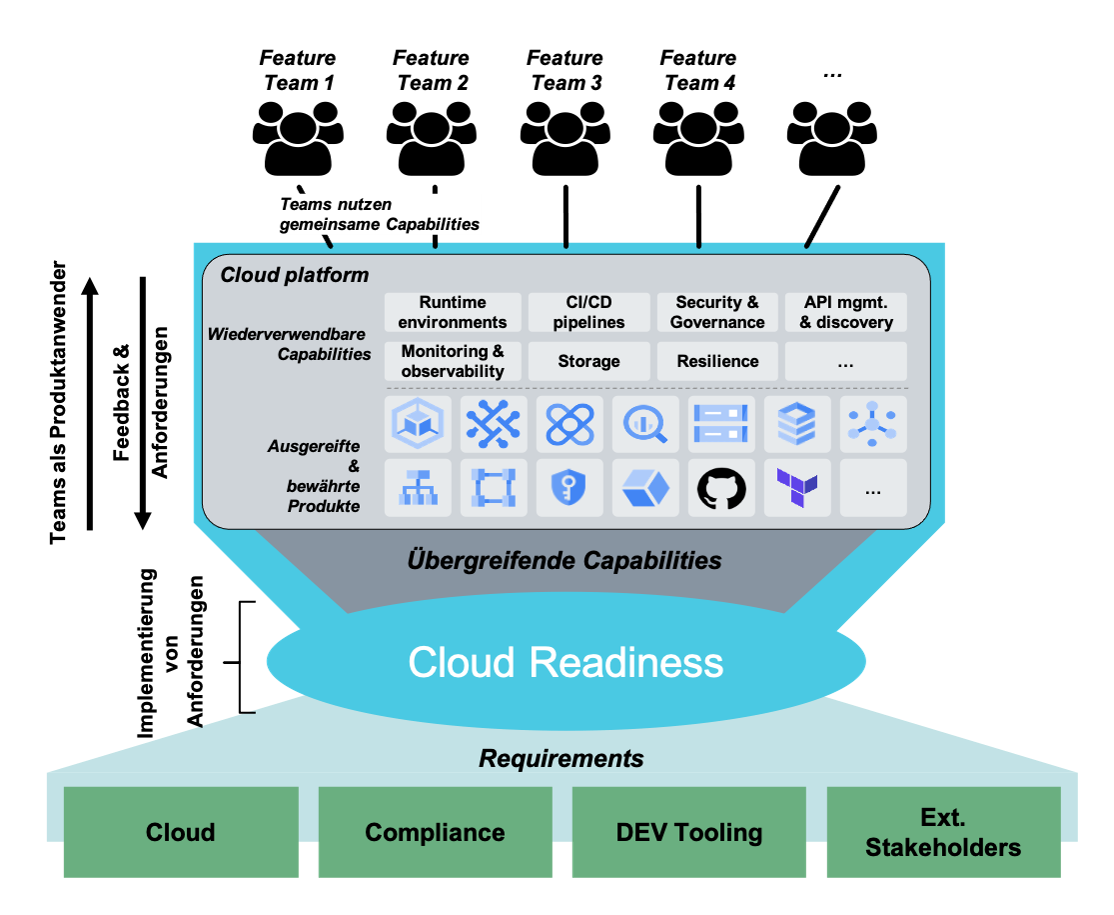
Struktur für ein zentrales Plattformteam
Die Hauptherausforderung hierbei ist die stetige Kommunikation mit den Featureteams. Da sich die Anforderungen der Teams schnell ändern können, müssen wir diese stetig erneut abfragen, um sicherzustellen, dass wir eine Plattform bereitstellen, welche einerseits die Anforderungen der Featureteams abbilden kann und andererseits mit den anderen zentralen Teams abgestimmt und abgenommen ist.
Damit wir als Platform Team nicht einfach nur die „Infrastrukturschubser“ sind, haben wir Produkte definiert, über welche auch wir iterieren können, um damit auch sinnvolle Produktinkremente liefern zu können. Dies erleichtert ebenso die Planung der Featureteams, da Anforderungen an unsere bereitgestellten Produkte einfach per Request an uns gerichtet werden können. Dies versetzt uns in die Lage, teamintern mit einer starken Produktorientierung zu arbeiten, was die Motivation und Innovation im Team gefördert hat. Das initiale Erstellen der Produkte welche wir anbieten, war nicht sonderlich einfach und ist definitiv kein Standardrezept für alle zukünftigen Projekte. Auch hierüber muss man wie ein normales Feature Team iterieren und bei Bedarf ggfs. neue Produkte anbieten, die bestehenden anpassen oder sogar Produkte „aus dem Sortiment nehmen“.
Wir haben uns bei der Cloud Migration für sechs grundlegende Produkte entschieden, die alle um das zentrale Thema „Security & Governance“ geschnitten sind bzw. sicher und (Banken-) konform out-of-the-box sind. Auf die aus unserer Sicht wichtigsten drei Komponenten möchten wir gerne etwas genauer eingehen.
Security & Governance
Security und Governance ist speziell in der Bankenwelt ein sehr komplexes Themengebiet und bedarf nicht unbedingt technischer Lösungen, sondern hauptsächlich eines prozessualen Umschwungs. Als zentrales Themengebiet einer Cloud Transformation sollte hierauf ein besonderer Fokus liegen. Diesem Fokus versuchen wir insbesondere durch einen “Shift left”-Ansatz gerecht zu werden, bei dem wir “Security-First” zu unserem Motto gemacht haben – bereits in den initialen Design- und Implementierungsphasen. Hierbei nutzen wir einen zero-trust Ansatz, also grundsätzlich nichts und niemandem zu vertrauen.
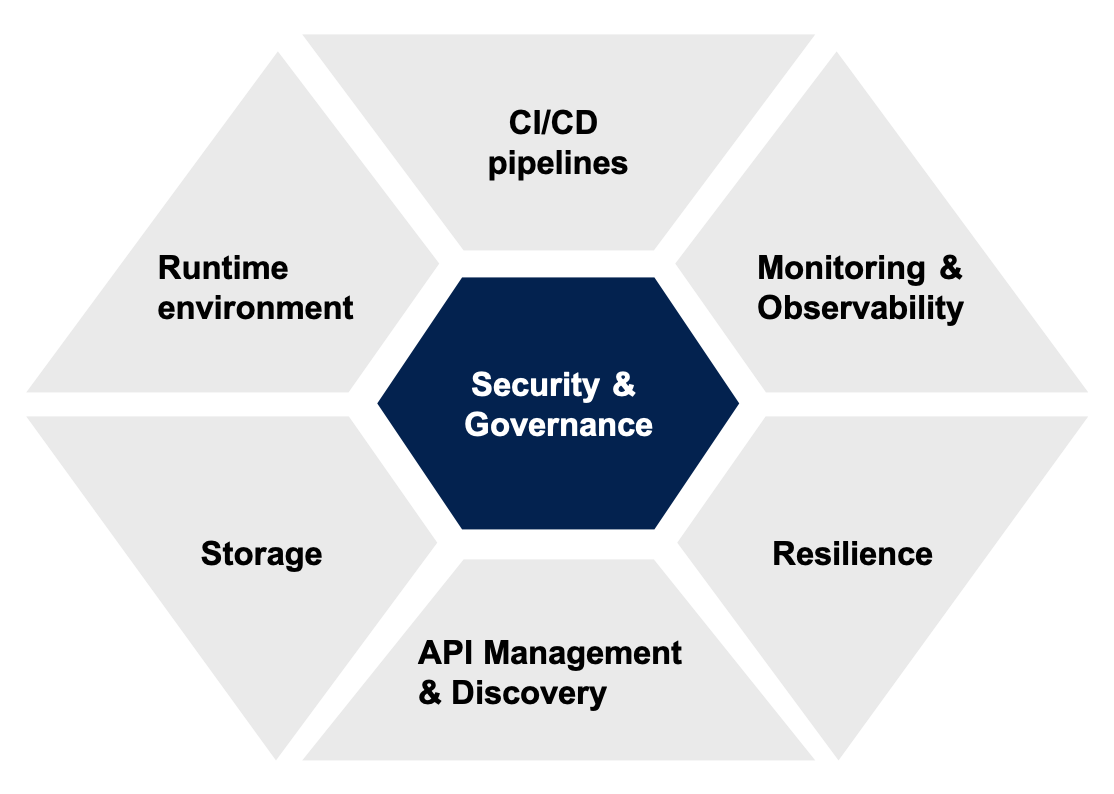
Produktübersicht des Plattformteams
Die Einbindung von dedizierten Security Engineers in unser Team ermöglicht uns, den Featureteams mehrere zentrale Themen abzunehmen wie z.B. Identity & Access Management (Stichwort “Least Privilege”), Security Scanning, Log Storage und Export Konzepte sowie das Härten und Absichern der Infrastruktur (Isoloated Workloads, Integrity Monitoring, mTLS). Die Automatisierung von Sicherheitsrichtlinien (Policy as Code) erhöht die Geschwindigkeit und senkt die Time to Market-Zeit, während wir das gleiche Qualitäts- und Sicherheitsniveau mit jedem Release garantieren können.
Am entscheidendsten zeigt sich jedoch die Absprachen mit den CiSo-Abteilungen. Gerade diese stellen sich als sehr große Herausforderung dar, da aktuell bei diesen noch sehr viele Unsicherheiten vorhanden sind bezüglich eines der Regulierung entsprechenden Cloud-Setups. Selbst mit intensiver Beratung unsererseits konnten wir viele der vorhandenen Prozesse nur stückweise auflockern bzw. Bedenken teilweise auflösen. Obwohl wir einen konsequenten Zero Trust-Ansatz verfolgen, wird wohl auch hier noch einige Zeit vergehen und Erfahrung im “Neuland” gesammelt werden müssen.
Runtime Environment
Während das Produkt Security & Governance zwar durchaus viele technische Aspekte mit sich bringt, ist es am Ende trotzdem eher ein „Absprachenprodukt“ zwischen den CiSo-Abteilungen und uns. Als Pendant hierzu steht das Produkt „Runtime Environment“, bei dem wir größtenteils die komplette Implementierungshoheit besitzen. Ziel ist die Bereitstellung einer den Anforderungen der Bank entsprechenden Umgebung für unsere Featureteams, so dass diese ihre Workload betreiben können.
Am interessantesten aus technischer Sicht ist hier die selbst auferlegte Aufgabe „Everything as Code – 100% Automatisierung jeglicher Komponenten“. Die Automatisierung stellt dabei für uns nicht nur einen Weg der Skalierung dar, sondern ermöglicht uns auch eine gleichbleibend hohe Qualität sicherzustellen. Beides sehen wir als unerlässlich für die Entwicklung und den Betrieb von Infrastruktur in der Cloud an. Konkret beschäftigen wir uns hauptsächlich mit der Bereitstellung und Konfiguration mehrerer Kubernetes Clusters. Hierzu zählt aber nicht alleine der Cluster, sondern auch Teilprodukte wie das Netzwerk-Setup, eine Service Mesh Konfiguration (mittels Istio Service Mesh) und auch z.B. die Infrastruktur für unser Frontend Serving. Abschließend gehört hier auch der Support für die Featureteams für Fragestellungen wie „Mein Deployment startet nicht – wer kann mir helfen“ dazu.
Die Hauptschwierigkeit dieses Produktes beläuft sich hier eher auf technischer Ebene: „Wie konfiguriere ich mein Service-Mesh“, „Wie kann ich Regional Failover Requirements abbilden“. Nichtsdestotrotz müssen wir auch hier häufig in enger Absprachen mit den zentralen Teams vorgehen. Zum Beispiel mit dem zentralen Netzwerk Team, welches sich um das gesamte Setup inklusive Firewall-Regeln in der Cloud kümmert.
CI/CD Pipelines
Neben der Bereitstellung einer Plattform zum Betrieb der Workloads jedes Featureteams stellen wir auch die dafür benötigten CI/CD-Pipelines bereit. Auch hier gilt für uns die Prämisse der vollständigen Automatisierung und insbesondere, dass jegliche Deployments vollautomatisiert sein müssen. Da nicht jedes Team das Rad einer CI/CD-Pipeline neu erfinden soll und die Bank zentrale Anforderungen an Deployments stellt, liefern wir den Teams Blueprints / Templates als Produkt zu.
Diese Templates sind optimiert für die jeweiligen Programmiersprachen und beinhalten neben den üblichen Build- und Deploy-Schritten weitere Schritte zur Sicherstellung der Compliance sowie der Einhaltung unserer Coding Conventions. Unter anderem haben wir eigene Security & Code Scanning steps eingeführt, welche parallel zu den Build & Deployment steps der Services oder des Frontends laufen. Alle Steps gemeinsam sammeln dabei Evidenzen und triggern vor dem finalen Deployment einzelne APIs einer zentralen Governance Plattform, welche automatisch die vorgegebenen Qualitätskontrollen auf Basis der Pipeline Ergebnisse schließt.
Hauptschwierigkeit im Bankenumfeld ist hier, dass meistens nicht alles automatisiert ist. Viele Kontrollen werden händisch erfüllt, zumeist durch lange Excel Tabellen, für deren Abarbeitung mehrere Projektmitglieder manchmal wochenlang geblockt sind. Unser Hauptfokus liegt dementsprechend insbesondere auch auf der weiteren Automatisierung dieser Kontrollen beziehungsweise der Neu-Definition für den Bereich Cloud.
Fazit
Wir haben mit einer produktorientierten Infrastrukturplattform und einem zentralen Team sehr gute Erfahrungen gemacht und würden dies grundsätzlich so auch wieder in Folgeprojekten machen:
- Die effektive Fertigungstiefe der Teams kann reduziert werden durch ein “Wohlfühlpaket” aus zentral gemanagten und bereitgestellten Komponenten und Tools. Featureteams können sich voll auf die Featureentwicklung für den Endkunden konzentrieren und müssen nicht jedes eingesetzte Tool kennen bzw. Kenntnisse darin aufbauen.
- Das zentrale Team behält die volle Verantwortung für die Plattform sowie Übersicht über die Anforderungen und damit die benötigten Infrastrukturkomponenten. Es kann somit Abhängigkeiten zu zentralen Teams koordinieren, kapseln und sicherstellen, dass angebotene Produkte den hohen Standards genügen und relevant für die Featureteams sind.
Natürlich kommt ein zentrales Team auch mit vereinzelten negativen Aspekten:
- In den Featureteams bildet sich weniger Wissen über die zugrundeliegende Plattform aus. Bei Problemen mit dieser herrscht dementsprechend teilweise wenig Selbstständigkeit bei der Lösungsfindung.
- Das Infrastrukturteam ist inhaltlich sehr weit entfernt von der eigentlichen Featureentwicklung. Daher ist viel Kommunikation und Austausch mit den Teams erforderlich, um bspw. Requirements der Teams zu kennen.
Final bleibt zu sagen, dass es kein „One-size-fits-all“ gibt. Man muss stets die Anforderungen im Hinterkopf behalten und abwägen ob ein zentrales Team alle Probleme löst. Grundsätzlich aber gilt, dass eine Cloud Infrastruktur hochkomplex ist und das „it just works“ des Marketingpitches selten die ersten Implementierungen überlebt.
